
'데이터 기반 마케팅' 확대에 따라 서로 다른 마케팅 활동을 설계하고 이에 대한 고객 반응을 비교/분석하는 "A/B 테스트" 역시 '스타트 업' 뿐만 아니라 일반 기업에 있어서도 조금씩 보편화되고 있는 추세이다.
A/B 테스트란 전통적인 통계의 집단 간 차이 분석과 마케팅 실행 프로세스를 결합한 기법으로 타겟 고객 세그먼트를 위한 가장 효과적인 '대안'을 발견하거나 분석의 인사이트를 통해 고객 세그먼트 별 최적 '대안'을 찾아내는 작업이다.
그러나 단순히 A와 B의 결과값만 비교해서는 의미 있는 인사이트를 얻기가 어렵다. 이에 통계적 검증을 통해 최적 대안을 발견해 나가는 A/B 테스트 사례에 관해 이야기해 본다.
어느 회사에서 기존의 회원을 대상으로 설 특별 세일을 알리는 이메일 시안 A와 B를 제작하고, 구매자를 대표할 수 있는 고객을 선별하여 A안, B안 각각 10명씩 테스트했다. 아래 표는 그 결과다[참고 1].
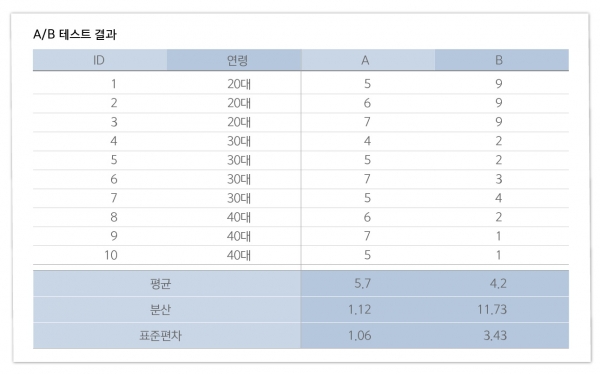
테스트 결과, A안의 평균 점수는 5.7점이고 B안의 평균 점수는 4.2점이다.
그럼 A안이 B안보다 우수하다고 말할 수 있는가?
마케터는 일단 표 안의 수치를 살피며 분산과 표준편차의 값에 주목한다[참고 2]. 분산은 데이터가 흩어진 정도이고, 표준편차는 분산의 제곱근으로 각 개별 데이터가 평균으로부터 떨어진 거리를 말한다. 일반적으로 분산과 표준편차가 적을수록 안정된 데이터 값을 가지고 있다고 말할 수 있다.
A안의 분산은 1.12, 표준편차는 1.06. B안의 분산과 표준편차는 4.2, 11.73. A안이 B안에 비해 안정된 분석 결과를 보이고 있다.
하지만 우리의 시장은 피험자 20명이 아니라(각 대안 평가 10명), 피험자 20명이 포함된 전체 목표 시장(모집단)이다. 이에 마케터는 테스트의 결과가 과연 목표 시장에서도 과연 의미 있는 것인지 통계적으로 검증해보기로 한다.
이 경우 두 집단간의 비교이므로 t-test를 통해 통계적으로 검증해 볼 수 있다[참고 3]. t-test란 두 집단의 통계적 차이를 검증하는 방법의 하나로 보통 SPSS, SAS, R 등의 전문 통계 패키지를 사용한다.
엑셀을 활용한 t-test 방법
통계 패키지를 이용하기 어려울 경우 간단히 엑셀을 활용하는 방법이 있다.
절차는 다음과 같다.
엑셀을 활용한 t-test의 경우, 등분산을 가정하는 경우와 그렇지 않은 경우가 있다. 이는 표본 데이터가 모집단의 정규분포를 가정할 수 있는지(등분산)를 확인하여 등분산을 가정하는 옵션 혹은 그렇지 않은 옵션을 선택하기 위해서다.
엑셀의 데이터>데이터분석을 클릭, 통계 데이터분석 창에서 F-검정을 클릭, 대화상자에서 상단에 A, 하단에 B 데이터를 입력한다(해당 셀 드래그&드롭).
유의수준 0.05(5%)라는 것은 95%의 신뢰구간에서 검증한다는 이야기이다.
확인을 누르면 다음의 결과를 얻을 수 있다.
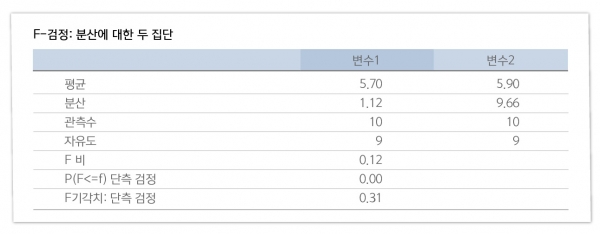
결과 화면의 P(F<=f) 단측 검정 결과인 0.00을 양측 검정을 위해 제곱을 해준다. 물론 결과는 0.00. F-검정의 경우, 양측 검정 결과의 확률이 0.05이상 나와야 등분산을 가정할 수 있는데 결과값이 0.05 미만이기에 t-test에 있어 '이분산을 가정한' 분석을 선택하기로 한다.
이제 실제 2개 집단 간의 비교를 위한 t-test를 진행한다. 엑셀 데이터 분석 메뉴에서 t-test, 그 중 '이분산을 가정한 t-test' 옵션을 선택한다.
마찬가지로 상단에 A안의 데이터를 입력하고 하단에 B안의 데이터를 입력한다. 그리고 확인.
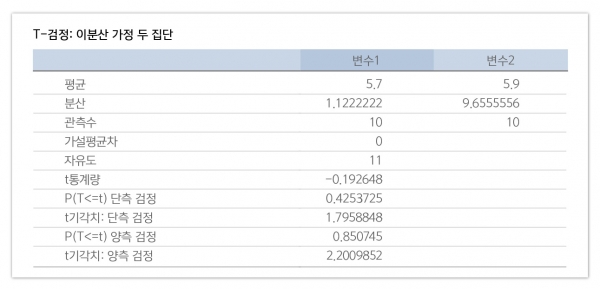
분석 결과, t-test의 P(T<=t) 양측 검정 결과는 0.85로 나왔다.
t-test 분석의 기본 가설은 '집단 간 차이가 없다'로서 결과값이 0.05 미만으로 나와야 차이가 없다는 가설을 기각하여 차이가 있다고 해석할 수 있다[참고 4].
그러나 분석 결과는 0.05보다 크므로 가설을 기각하지 못하여 차이가 없다고 할 수 있다. 즉, 이번 A/B 테스트의 경우 A안이 B안보다 우수한 것으로 나타났으나, 이는 우연일 수 있으며 실제 목표 시장(모집단)에 반영할 시 A와 B의 차이는 없을 수 있다는 것이다.
마케터는 멘탈붕괴 직전이다. ‘Live 할 날이 얼마 남지 않았는데 테스트 시안부터 다시 제작해야 하나? 아니면 그냥 A안으로 결정할까?’
그런데 B안을 가만히 살펴보니 분산과 표준편차가 크게 나온 것은 20대 연령층과 그 이상 연령층의 차이에서 비롯되지 않았을까? 라는 생각이 든다. 이에 B안을 대상으로 20대 연령층과 그 이상의 연령층으로 집단을 나누고 t-test를 수행한다.
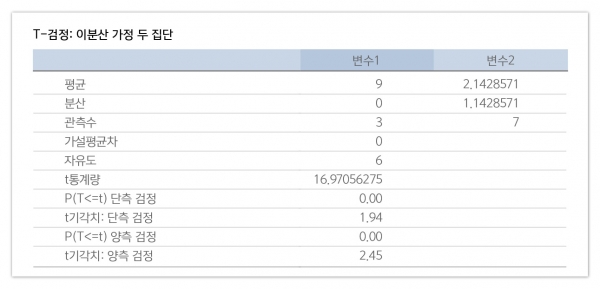
분석 결과, P(T<=t) 양측 검정 결과는 0.00.
0.05보다 작음으로 B안의 20대와 그 이상 연령의 평균 차이는 통계적으로 유의하다.
마케터는 다시 생각한다.
A안과 B안의 첫 번째 분석 결과, 비록 평균은 A안이 높았으나 통계분석 결과 사실 어느 쪽이 더 우수하다고는 할 수 없었다. 그러나 B안의 경우 20대 연령층의 압도적 지지(평균 9점)를 얻었고 t-test 결과, 다른 연령층과도 차이가 있다는 것을 통계적으로 검증할 수 있었다.
그럼 20대 고객에게는 B안으로 커뮤니케이션하고, 30대에서 40대 연령층에게는 평가 결과가 좋은 A안으로 커뮤니케이션하면 되지 않을까? 만일 그렇다면 30대와 40대 연령층에게 A안과 B안의 차이가 통계적으로 검증되면 된다.
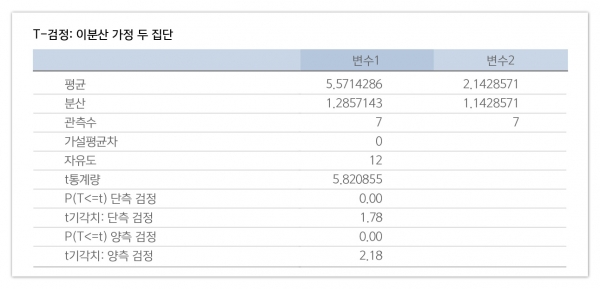
P(T<=t) 양측 검정의 결과값은 0.00.
역시 30대와 40대 연령층에게 A안(평균: 5.57)이 B안(평균: 2.14)에 비해 평가가 우수함을 통계적으로 검증할 수 있었다. 여기서 통계적 검증이란 표본의 차이가 전체 목표 시장(모집단)에서도 똑 같은 차이가 나타날 수 있다는 것을 확인한 것이다.
이제 마케터는 실행기획을 도출해 볼 수 있다.
"20대 고객에게는 B안으로, 30대와 40대 고객에게는 A안으로 커뮤니케이션하자"
위의 이야기는 가정된 사례이며, 차이 분석과 통계적 방법론에 관한 구체적 내용은 상당부분 생략하였다. 또한 통계적으로 유의하다는 것이 반드시 시장에서 유의한 결과로 나타난다고도 할 수 없다.
그리고 A/B테스트는 표본 샘플링 뿐만 아니라 전수 데이터를 대상으로 할 수 있으며, 분석 역시 t-test에 한정되지 않을 것이다. 또한 분석보다는 비교기준이 타당한 A와 B의 설계 등 엄정한 조사 계획이 더욱 중요하다.
그러나 마케터는 데이터 분석 결과를 통해 언제나 우리가 겨냥하는 목표 시장 전체를 추정해야 한다는 관점을 잃지 않기를 바라며 흔히 활용할 수 있는 엑셀을 통한 평균의 검증법을 소개해 본다.
[참고]
1. 예시는 10개의 데이터에 한정했으나 통계분석을 위해서는 정규분포를 가정할 수 있는 30개 이상의 데이터를 갖추어야 한다. 30개 미만일 경우 비모수 통계기법을 적용해야 한다. 본 내용은 예시임을 다시 한번 밝혀 둔다.
2. 엑셀함수
1) 분산: =VAR 2) 표준편차: =STDEV
3. 3개 집단 이상의 차이비교일 경우 분산분석 혹은 기타 방법을 적용한다.
4. F-검정의 경우 기본 가설은 ‘등분산이다’ 이다. 결과값이 0.05보다 작게 나오면 등분산이 아닌 것이며 0.05보다 크게 나와야 등분산이라고 할 수 있다.
김신엽 경영학 박사, 부산국제광고제 애드텍 집행위원
